
The Digital Civil Society Lab at Stanford recently hosted a small gathering of people to dig into emerging processes for ethical data review. This post is a write up of the publicly shareable discussions there.
Introduction
Lucy Berholz opened the day by talking about “digital civil society” as an independent space for civil society in the digital sphere. She is specifically concerned with how we govern the digital sphere in line with the a background of democracy theory. We need to use, manage, govern in ways that are expansive and supportive for independant civil society. This requires new governance and review structures for digital data.
This prompted the question of what is “something like an IRB and not an IRB”? The folks in the room bring together corporate, community, and university examples. These encompass ethical codes and the processes for judging adherence to them. With this in mind, in the digital age, do non-profits need to change? What are the key structures and governance for how they can manage private resources for public good?
Short Talks
Lasanna Magassa (Diverse Voices Project at UW)
Lasanna introduced us all to the Diverse Voices Project, an “An exploratory method for including diverse voices in policy development for emerging technologies”. His motivations lie in the fact that tech policy is generally driven by mainstream interests, and that policy makers are reactive.
They plan and convene “Diverse Voices Panels”, full of people whole live an experience, institutions that support them, people somehow connected to them. In a panel on disability this could be people who live it and are disabled, law & medical professionals, and family members. These panels produce whitepapers that document and then make recommendations. They’ve tackled everything from ethics and big data, to extreme poverty, to driverless cars. They focus on what technology impacts can be for diverse audiences. One challenge they face is finding and compensating panel experts. Another is wondering how to prep a dense, technical document for the community to read.
Lasanna talks about knowledge generation being the key driver, building awareness of diversity and the impacts of technologies on various (typically overlooked) subpopulations.
Eric Gordon (Engagement Lab at Emerson College)
Eric (via Skype) walked us through the ongoing development of the Engagement Lab’s Community IRB project. The goal they started with was to figure out what a Community IRB is (public health examples exist). It turned out they ran into a bigger problem – transforming relationships between academia and community in the context of digital data. There is more and more pressure to use data in more ways.
He tells us that in Boston area, those who represent poorer folks in the city are asked for access to those populations all the time. They talked to over 20 organizations about the issues they face in these partnerships, focusing on investigating the need for a new model for the relationships. One key outcome was that it turns out nobody knows what an IRB is; and the broader language use to talk about them is also problematic (“research”, “data”).
They ran into a few common issues to highlight. Firstly, there weren’t clear principles for assuring value for those that give-up their data. In addition, the clarity of the research ask was often weak. There was a all-to-common lack of follow-through, and the semester-driven calendar is a huge point of conflict. An underlying point was that organizations have all this data, but the outside researcher is the expert that is empowered to analyze it. This creates anxiety in the community organizations.
They talked through IRBs, MOUs, and other models. Turns out people wanted to facilitate between organizations and researchers, so in the end what they need is not a document, but a technique for maintaining relationships. Something like a platform to match research and community needs.
Molly Jackman & Lauri Kanerva (Facebook)
Molly and Lauri work on policy and internal research management at Facebook. They shared a draft of the internal research review process used at Facebook, but asked it not be shared publicly because it is still under revision. They covered how they do privacy trainings, research proposals, reviews, and approvals for internal and externally collaborative research.
Nicolas de Corders (Orange Telekom)
Nicolas shared the process behind their Data for Development projects, like their Ivory Coast and Senegal cellphone data challenges. The process was highly collaborative with the local telecommunications ministries of each country. Those conversations produced approvals, and key themes and questions to work on within the country. This required a lot of education of various ministries about what could be done with the cellphone call metadata information.
For the second challenge, Orange set up internal and external review panels to handle the submissions. The internal review panels included Orange managers not related to the project. The external review panel tried to be a balanced set of people. They built a shared set of criteria by reviewing submissions from the first project in the Ivory Coast.
Nicolas talks about these two projects as one-offs, and scaling being a large problem. In addition, getting the the review panels to come up with shared agreement on ethics was (not surprisingly) difficult.
Breakouts
After some lunch and collaborative brainstorming about the inspirations in the short talks, we broke out into smaller groups to have more free form discussions about topics we were excited about. These included:
- an international ethical data review service
- the idea of minimum viable data
- how to build capacity in small NGOs to do this
- a people’s review board
- how bioethics debates can be a resource
I facilitated the conversation about building small NGO capacity.
Building Small NGO Capacity for Ethical Data Review
Six of us were particularly interested in how to help small NGOs learn how to ask these ethics questions about data. Resources exist out there, but not well written enough for people in this audience to consume. The privacy field especially has a lot of practice, but only some of the approaches there are transferrable. The language around privacy is all too hard to understand for “regular people”. However, their approach to “data minimization” might have some utility.
We talked about how to help people avoid extractive data collection, and the fact that it is disempowering. The non-profit folks in the group reminded us all that you have to think about the funder’s role in the evidence they are asking for, an how they help frame questions.
Someone mentioned that law can be the easiest part of this, because it is so well-defined (for good or bad). We have well established laws on the fundamental privacy right of individuals in many countries. I proposed participatory activities to learn these things, like perhaps a group activity to try and re-identify “anonymized” data collected from the group. Another participant mentioned DJ Patel’s approach to building a data culture.
Our key points to share back with the larger group were that:
- privacy has inspirations, but it’s not enough
- communications formats are critical (language, etc); hands-on, concrete, actionable stuff is best
- you have to build this stuff into the culture of the org



 I’ve written a bunch about data literacy and the variety of ways I try to build it with community groups, but we received strict instructions to focus this conversation on visualization. That was hard! So we started off by making sure we understood the audiences we were talking about – people who make visualizations and people who see/read them. So many ways to think about this… so many questions we could address… we were lost for a bit about where to even start!
I’ve written a bunch about data literacy and the variety of ways I try to build it with community groups, but we received strict instructions to focus this conversation on visualization. That was hard! So we started off by making sure we understood the audiences we were talking about – people who make visualizations and people who see/read them. So many ways to think about this… so many questions we could address… we were lost for a bit about where to even start!
 We have a vast, and growing array of visualization techniques available to us, but few guidelines on how to use them appropriately for different audiences. This is problematic, and a responsible version of data visualization should respect where and audience is coming from and their visual literacy. With that in mind, we propose to create a library of case studies where each one creates different visualizations from the same dataset, making the same argument, for different audiences.
We have a vast, and growing array of visualization techniques available to us, but few guidelines on how to use them appropriately for different audiences. This is problematic, and a responsible version of data visualization should respect where and audience is coming from and their visual literacy. With that in mind, we propose to create a library of case studies where each one creates different visualizations from the same dataset, making the same argument, for different audiences. Our idea here was to create a quick how-to guide that lists things you should ask when reading a data visualization. Imagine a
Our idea here was to create a quick how-to guide that lists things you should ask when reading a data visualization. Imagine a  This is a huge problem. The hype around data visualization continues to grow, and more and more tools are being created to help non-experts make them. Unfortunately, the materials we use to help these newcomers into the field haven’t kept pace with the huge rise in interest!
This is a huge problem. The hype around data visualization continues to grow, and more and more tools are being created to help non-experts make them. Unfortunately, the materials we use to help these newcomers into the field haven’t kept pace with the huge rise in interest!




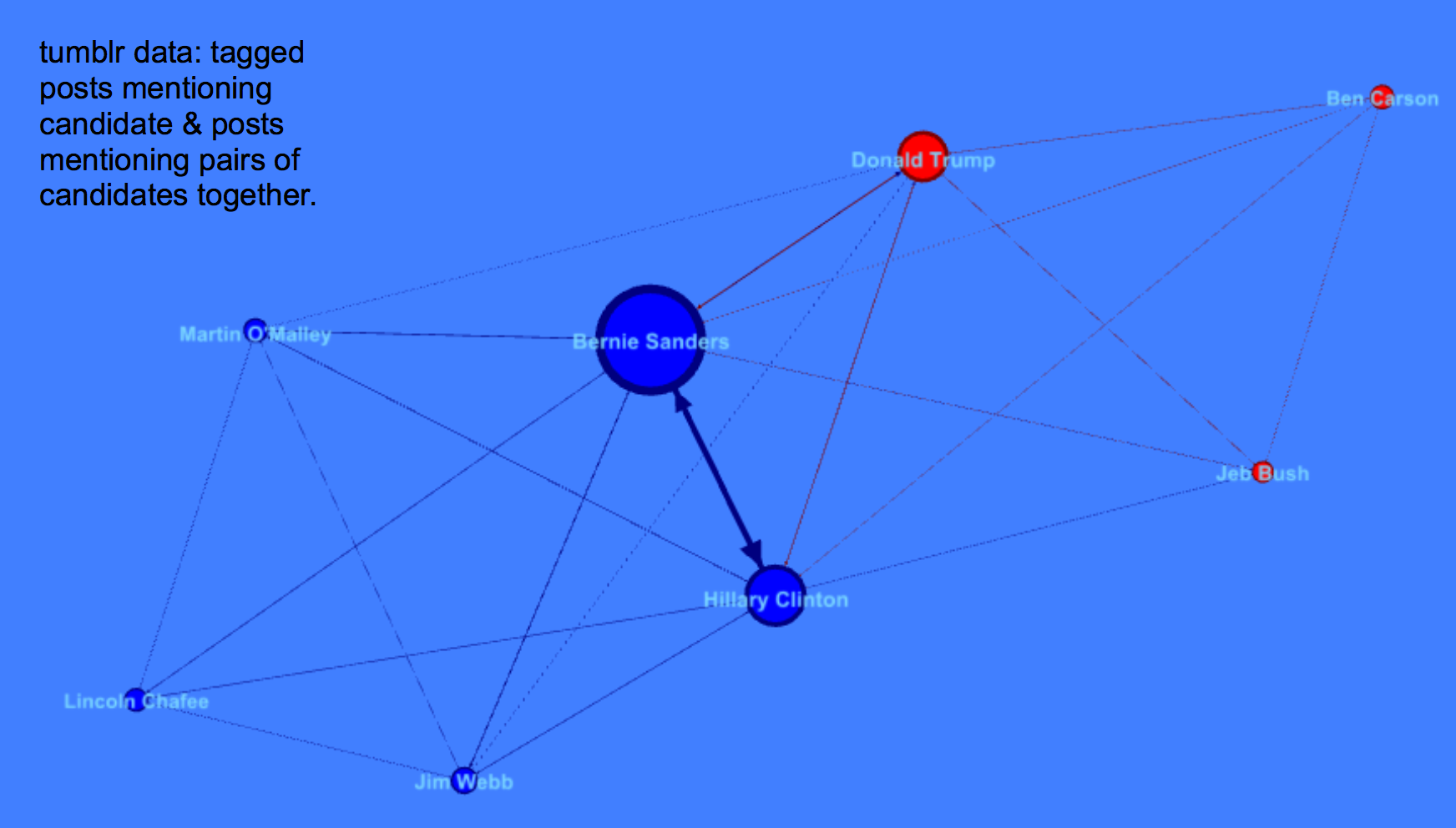
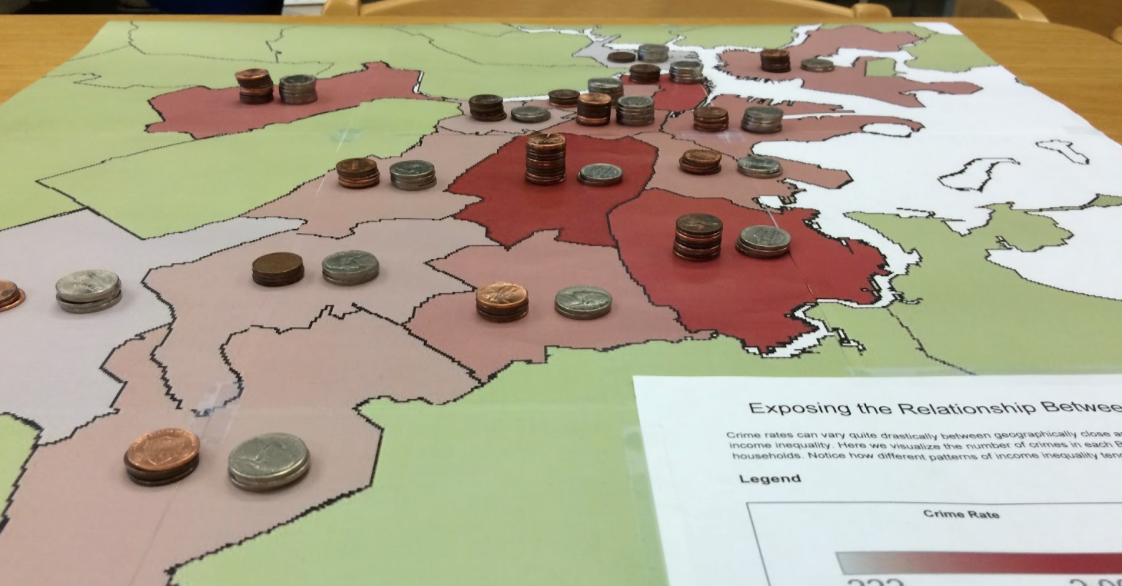



You must be logged in to post a comment.